
近日,CVPR 2026(国际计算机视觉与模式识别会议)召开,理想汽车共有12篇论文入选。CVPR是计算机视觉与模式识别领域的顶级学术会议,与ICCV(国际计算机视觉大会)、ECCV(欧洲计算机视觉国际会议)并称为计算机视觉领域三大顶级会议,具有极高的学术影响力。理想汽车此次入选12篇论文,涵盖多模态感知、端到端规划、世界模型、强化学习、认知模型及语言智能等多个核心领域,系统性展现了理想汽车持续深耕具身智能技术领域的研究实力。
从感知到决策 带来全新技术范式
感知能力是具身智能的认知起点。在多模态感知领域,理想汽车SparseWorld-TC论文被收录为Oral(大会口头报告),SparseWorld-TC全新架构突破了传统方法依赖鸟瞰图投影和离散化token表示的双重瓶颈,直接从原始图像特征端到端预测多帧未来三维场景占据情况。该方法采用稀疏占据表示,使Transformer能够更高效地建模时空依赖关系,在nuScenes基准上的1至3秒占据预测任务中达到当前最优性能,并在任意未来轨迹条件下保持较高精度,为智能辅助驾驶提供更精准的环境预判能力。
在端到端规划领域,理想汽车提出SGDrive框架,将驾驶理解分解为“场景-交通参与体-目标”的层级结构,这一设计与人类驾驶认知方式高度对应:驾驶员首先感知整体环境,继而识别关键交通参与体及其行为,最后形成短期目标并执行动作。SGDrive通过结构化的时空表示弥补了通用视觉语言模型在驾驶场景中的认知空缺,在NAVSIM基准上的纯视觉方案中取得当前最优性能,验证了层级化知识结构对于提升智能辅助驾驶规划能力的有效性。
在强化学习领域,理想汽车提出PlannerRFT框架,解决了基于扩散模型的规划器在强化微调过程中难以生成多模态、场景自适应轨迹的核心难题。PlannerRFT采用双分支优化策略,在不改变原始推理流程的前提下,同时优化轨迹分布并自适应引导去噪过程。为支持大规模并行学习,理想汽车同步开发了nuMax仿真器,其轨迹推演速度较原生nuPlan提升10倍,为强化学习在智能辅助驾驶中的高效应用提供了基础设施支撑。
世界模型四项突破 夯实智能辅助驾驶仿真与安全基座
世界模型是此次理想汽车论文入选最为集中的领域,共有4篇论文入选,覆盖深度估计、三维重建、认知评估与安全预判四大方向。InfiniDepth论文针对传统深度估计中离散网格表示分辨率受限、难以恢复精细几何细节的行业痛点,创新性地将深度建模为神经隐式场,支持任意分辨率的连续稠密深度查询,在精细细节区域和度量深度估计上均表现优异,为新视角合成提供了更为精确的几何先验,有效提升大基线场景下的渲染质量。
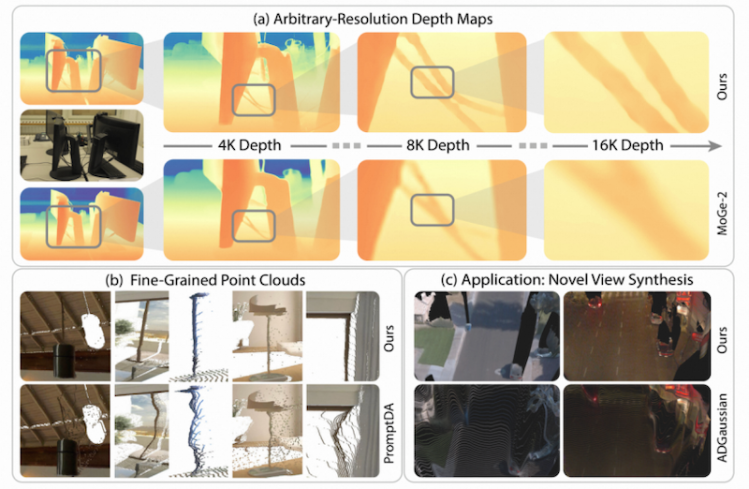
InfiniDepth
Unposed-to-3D论文聚焦于智能辅助驾驶仿真对高质量三维车辆资产的迫切需求。针对现有方法依赖合成数据训练且需要精确相机位姿标注、与真实场景存在域差距的问题,该研究提出两阶段框架,通过相机预测头结合可微渲染实现无位姿图像的自监督学习,最终从真实驾驶图像中直接重建出尺度准确、外观和谐的仿真就绪三维车辆,显著降低了仿真资产的生产门槛。
DriveCombo论文揭示了当前多模态大语言模型在复杂交通规则理解上的真实能力边界。现有基准仅覆盖单一规则场景,无法反映真实驾驶中多规则并发与冲突的推理难度。该研究构建了文本与视觉双模态基准,提出五级认知阶梯,覆盖从单规则理解到冲突消解的全认知链路,对14个主流模型的评估揭示了任务复杂度与性能下降之间的系统性规律,并验证了该基准对提升下游规划能力的实际价值。
AD-R1入选CVPR Findings,该论文致力于解决将强化学习应用于端到端智能辅助驾驶时的核心障碍——世界模型因仅在安全专家数据上训练而存在系统性乐观偏差,面对危险轨迹时倾向于预测虚假的安全结果。该研究提出反事实合成流水线,将世界模型训练为公正的因果预测器,并将其整合进闭环强化学习框架作为危险感知评论器,有效降低了仿真场景中的安全违规率,为智能辅助驾驶的安全可靠性提供了新的技术路径。
认知对齐与语言、视觉智能 让推理更准更快
在认知模型领域,当前基于视觉语言模型的方法逐帧处理独立图像的方案,缺乏对历史状态的显式建模,导致决策抖动频繁。CogDriver论文研究提出认知惯性机制,通过构建大规模叙事式视觉—语言—动作数据集提供时序监督信号,并设计带有稀疏时序记忆模块的智能体架构,结合时空知识蒸馏显式训练决策一致性,在Bench2Drive和nuScenes基准上分别实现22%的驾驶得分提升和21%的轨迹误差降低,进一步解决了智能辅助驾驶规划中的时序一致性难题。
LinkVLA论文则聚焦于视觉语言动作模型中语言指令与动作输出不匹配、自回归动作生成效率低下两大痛点。该研究通过结构连接将语言和动作特征统一编入共享离散码本,从底层强制实现跨模态一致性;同时引入“动作理解”辅助任务促进语言与动作的双向映射,并采用粗到细的两步法替代传统逐步解码。闭环自动驾驶基准测试表明,LinkVLA在显著提升指令遵循准确性和驾驶性能的同时,节省了86%的推理延迟。
在语言智能领域,FastMMoE入选CVPR Findings,该论文提出一套面向基于MoE(混合专家)架构的多模态大模型、无需重新训练的加速优化框架,为多模态大模型的高效部署提供了新的技术路径。针对多模态大模型计算开销大、部署效率受限的行业痛点,FastMMoE从路由行为分析切入,融合视觉Token专家激活精简与路由感知式Token剪枝两套互补方案,在不牺牲核心能力的前提下大幅削减冗余计算。基于DeepSeek-VL2、InternVL3.5等主流模型的验证实验表明,FastMMoE最高可削减55%的浮点运算量,同时保留95.5%的原始性能,整体效果持续优于现有剪枝基线方法。
CoV-Align论文提出一种高效细粒度对齐框架,解决了多模态模型中图像区域与语言描述精准匹配时计算效率低、特征噪声大的双重难题。该研究创新性地提出“内聚视觉语义优先”策略,在不依赖文本引导的前提下,预先通过视觉信息自主聚合语义一致的图像区域,从而实现高效精准的区域—单词对齐。在Flickr30K和MS-COCO经典图文评测基准上,CoV-Align取得当前最优性能,推理速度较前沿基线方法提升3至5倍,在大规模多模态任务中展现出突出的实用优势。
在视觉智能领域,Switch-KD入选CVPR Findings,用一套跨模态知识新蒸馏范式以小博大,让0.5B的小模型拥有了逼近1.5B模型的多模态理解力。该方法突破了传统蒸馏“模态分离监督”的瓶颈,彻底重构了跨模态知识蒸馏的底层逻辑——从“各管一段”的模态分离监督,转向统一概率空间蒸馏,为车端边缘计算、智能座舱等轻量化部署场景提供了关键技术支撑。
理想汽车始终将基础研究视为支撑长期发展的核心动力。截至2026年一季度末,理想汽车已连续5个季度保持30亿元左右的高强度研发投入,并连续6年持续加码研发投入。2025年全年研发费用达到113亿元,为历史新高。近5年,理想汽车围绕多模态感知、端到端、认知模型、世界模型、强化学习和基座模型等核心技术方向,在CVPR、ICCV、ECCV、NeurIPS、SIGGRAPH、IROS、ICRA等顶级学术会议和期刊上发表近百篇论文,持续印证理想汽车技术研究的前沿性和影响力。
在基础研究过程中,理想汽车积极与国内外高校展开合作,践行“产学研结合”的创新模式,将自身在实际应用中积累的数据和工程经验反馈学术研究,推动产学研互利共赢。理想汽车的每一项研究成果和技术突破都指向同一个目标:以更强的技术积累兑现“给车和家赋予生命”的品牌使命,让每个家庭都能享受到智能科技带来的便利。未来,理想汽车将持续加大基础研究与应用创新的投入,以扎实的技术积累和开放的生态理念,迈向全球领先的具身智能企业。(资料来源:理想汽车)



1、“国际在线”由中国国际广播电台主办。经中国国际广播电台授权,国广国际在线网络(北京)有限公司独家负责“国际在线”网站的市场经营。
2、凡本网注明“来源:国际在线”的所有信息内容,未经书面授权,任何单位及个人不得转载、摘编、复制或利用其他方式使用。
3、“国际在线”自有版权信息(包括但不限于“国际在线专稿”、“国际在线消息”、“国际在线XX消息”“国际在线报道”“国际在线XX报道”等信息内容,但明确标注为第三方版权的内容除外)均由国广国际在线网络(北京)有限公司统一管理和销售。
已取得国广国际在线网络(北京)有限公司使用授权的被授权人,应严格在授权范围内使用,不得超范围使用,使用时应注明“来源:国际在线”。违反上述声明者,本网将追究其相关法律责任。
任何未与国广国际在线网络(北京)有限公司签订相关协议或未取得授权书的公司、媒体、网站和个人均无权销售、使用“国际在线”网站的自有版权信息产品。否则,国广国际在线网络(北京)有限公司将采取法律手段维护合法权益,因此产生的损失及为此所花费的全部费用(包括但不限于律师费、诉讼费、差旅费、公证费等)全部由侵权方承担。
4、凡本网注明“来源:XXX(非国际在线)”的作品,均转载自其它媒体,转载目的在于传递更多信息,丰富网络文化,此类稿件并不代表本网赞同其观点和对其真实性负责。
5、如因作品内容、版权和其他问题需要与本网联系的,请在该事由发生之日起30日内进行。



