
3月17日,理想汽车基座模型负责人詹锟出席NVIDIA GTC 2026,发表主题演讲《MindVLA-o1:开启全能范式——下一代统一视觉-语言-动作自动驾驶大模型探索》,发布下一代自动驾驶基础模型MindVLA-o1。MindVLA-o1通过五大技术创新,构建了面向物理世界智能的自动驾驶基础模型,让自动驾驶看得更远、想得更深、行得更稳、进化更快、部署更高效。
詹锟表示:“当我们把视觉、语言和行动统一到一个模型中时,它已不再只是自动驾驶模型,而是在逐渐演化为面向物理世界的通用智能体。基于同一套VLA模型,不仅可以控制车辆,也能够扩展到机器人。因此,自动驾驶只是物理AI的起点,未来这类基础模型将驱动新的具身智能范式。”
从规则时代到AI时代 理想辅助驾驶持续演进
自2021年启动辅助驾驶自研以来,理想辅助驾驶技术架构经历了多轮关键迭代,持续的技术探索与工程实践,为理想汽车在软硬件一体化研发领域积累了深厚的基础研究能力与研发实力。2024年是理想辅助驾驶的重要分水岭,随着端到端+VLM(视觉语言模型)双系统架构量产交付,辅助驾驶首次真正具备了跨场景、跨任务的统一理解能力。2025年,理想汽车进一步将空间理解、语言理解与行动决策统一到同一模型框架,构建了基于VLA、世界模型与强化学习三大技术栈的VLA司机大模型,并于8月随理想i8交付正式推送,9月向AD Max用户全量推送。
截至2025年底,VLA司机大模型月使用率达到80%,VLA指令累计使用1225.4万次;春节期间理想辅助驾驶总里程达2.5亿公里,VLA指令使用次数达130.3万次。规模化的用户验证与持续积累的真实场景数据,为理想汽车推进下一代自动驾驶技术演进提供了坚实基础。
MindVLA-o1五大技术创新:看得更远、想得更深、行得更稳、进化更快、部署更高效
理想汽车提出下一代统一架构——MindVLA-o1。该架构以原生多模态MoE Transformer为核心,通过五大技术创新——3D空间理解、多模态思考、统一行为生成、闭环强化学习(Closed-loop RL)和软硬件协同设计(Hardware–Software Co-Design),构建了面向物理世界智能的自动驾驶基础模型。
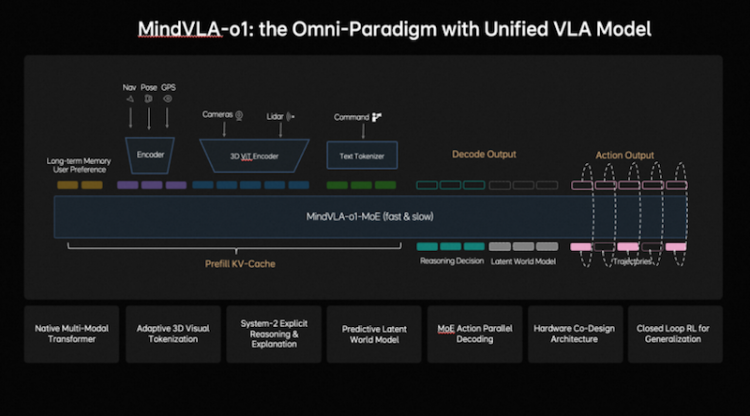
在感知层面,理想汽车采用以视觉为核心的 3D ViT Encoder(3D视觉模型编码器),并利用激光雷达点云作为三维几何提示,引导模型理解真实空间结构,使其在单一表示中同时具备语义理解与三维感知能力。同时引入前馈式3DGS表示(Feedforward 3D Representation),将场景拆分为静态环境与动态物体分别建模,并通过下一帧预测(Next-state prediction)作为自监督信号,使模型同时学习深度信息、语义结构与物体运动,最终形成融合空间结构与时间上下文的高质量3D表示。具备3D空间理解能力,使模型看得更远。

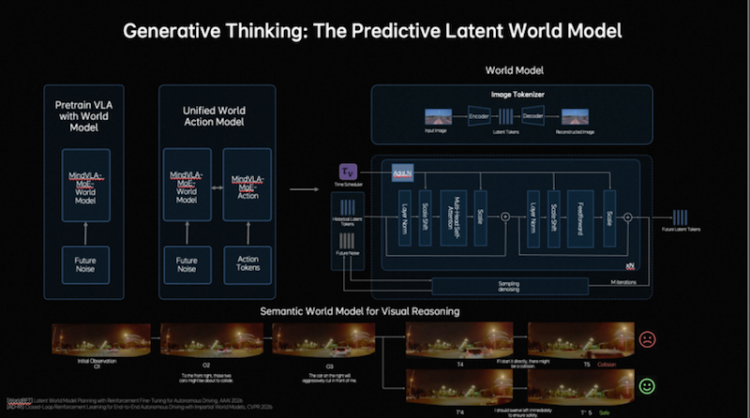
在思考层面,自动驾驶既要理解当前环境,也要预测未来几秒的场景演化。在语言模型承担语义理解、常识知识和交互能力的基础上,理想汽车还引入了预测式隐世界模型,在隐空间中高效模拟未来。训练分三阶段:第一,用海量视频数据预训练Latent World Token(隐世界词元),构建未来表征;第二,在MindVLA-o1中持续世界模型的推演,形成隐空间的未来推理能力;第三,将世界模型、多模态推理能力及驾驶行为进行联合训练与对齐。由此,模型不仅能理解当前场景并进行逻辑判断,还能在隐空间中提前“想象”未来画面,将驾驶决策具象化。理想汽车将这种能力定义为多模态思考(Generative Multimodal Thinking)。拥有多模态思考能力,让模型想得更深。
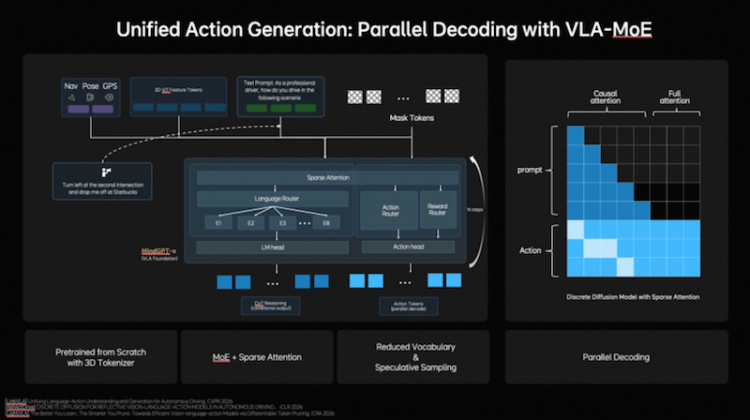
在行为层面,理想汽车构建了统一行为生成(Unified Action Generation)机制。首先,MindVLA-o1使用VLA-MoE(混合专家模型)架构,并引入专门的Action Expert(动作专家),从3D场景特征、导航目标、驾驶指令等多维输入中提取信息,并结合多模态思考生成高精度驾驶轨迹。其次,为满足实时性要求,系统采用并行解码(Parallel Decoding),同时生成所有轨迹点,大幅提升效率。最后,引入Discrete Diffusion(离散扩散)进行多轮迭代优化,类似逐步去噪,确保轨迹空间连续、时间稳定,并符合车辆动力学约束。形成统一行为生成机制,使模型行得更稳。
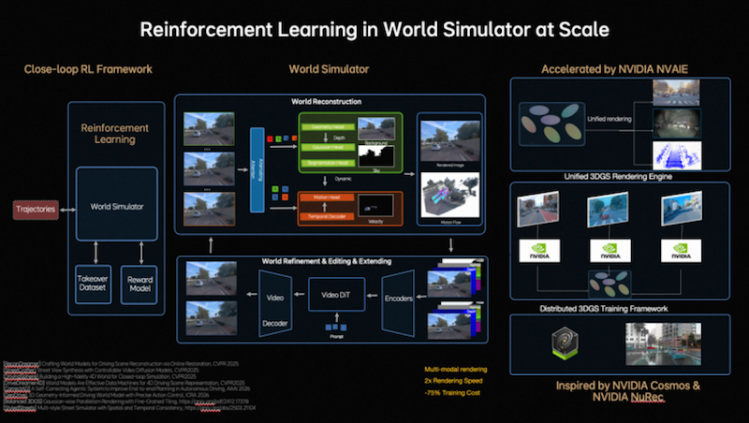
在模型迭代层面,理想汽车构建了闭环强化学习框架,让模型不仅能从真实数据学习,还能在世界模拟器(World Simulator)中持续探索和优化策略。为此,理想汽车将传统逐步优化式重建升级为Feed-forward(前馈)场景重建,使系统能够瞬时生成大规模、高保真驾驶场景,支持大规模并行训练。同时,结合生成式模型(Generative Models),模拟环境可扩展、编辑并生成全新场景。为支持大规模模拟与训练,理想汽车开发了统一的3D Gaussian Splatting(3D高斯泼溅)渲染引擎和分布式训练框架,渲染速度提升近2倍,整体训练成本降低约75%,实现低成本、高效率的强化学习闭环。在闭环强化学习框架下,模型实现更快进化。
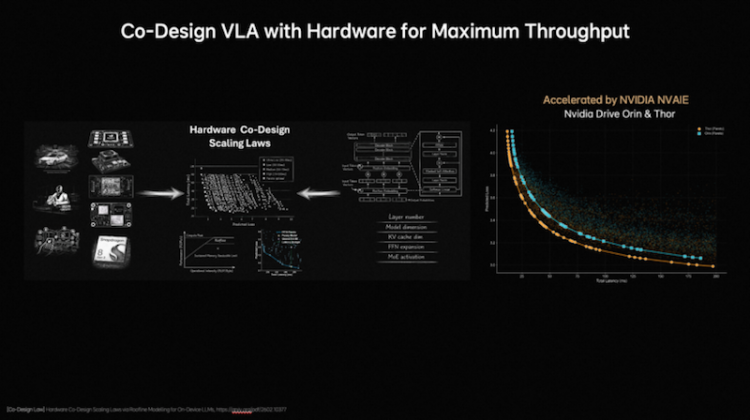
为解决传统端侧大模型部署耗时长、调试频繁的问题,理想汽车提出面向端侧大模型的软硬件协同设计定律,将模型结构与验证损失建模,并结合Roofline模型刻画硬件计算能力与内存带宽限制,在模型性能与硬件约束之间建立统一的分析框架。理想汽车基座模型团队评估了近2000种模型架构配置,在英伟达Orin与Thor平台上完成验证,找到了模型精度与推理延迟之间的Pareto Front(帕累托前沿),将架构探索时间从数月缩短至数天,大幅提升端侧VLA模型的设计与部署效率。在软硬件协同设计定律下,模型部署更高效。
自动驾驶只是起点 为具身智能构建“数字大脑”
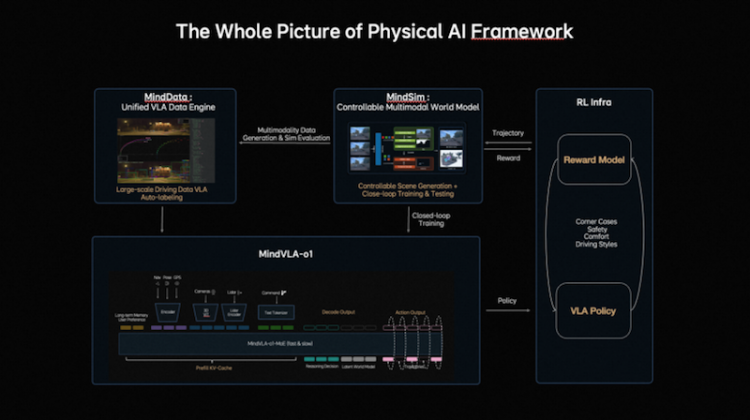
MindVLA-o1是理想汽车面向物理世界智能核心AI框架的重要组成部分。这套AI框架由四大核心模块组成:MindData,统一的VLA数据引擎,负责大规模数据的采集、清洗和自动标注;MindVLA-o1,统一的原生多模态VLA模型,可以理解环境、进行推理,并生成驾驶行为;MindSim,可控的多模态世界模型,用于生成复杂驾驶场景并支持大规模闭环训练;RL Infra(强化学习基础设施),通过奖励模型和策略学习,使系统在仿真与真实环境中自我进化。
四部分协同形成完整闭环,使AI能够感知、理解并在物理世界中自主行动,并持续学习。从结构上看,这套系统如同一个“数字大脑”:感知层对应视觉皮层,推理与规划如前额叶,场景生成似运动皮层,强化学习则类似多巴胺反馈,实现了感知、理解、行动和持续优化的完整闭环。
该框架不仅服务于汽车,也可扩展至机器人及各种物理系统。对理想汽车而言,车是最大号的机器人,其本质是在构建硅基生命体的躯干与大脑。
理想汽车在持续推进技术创新的同时,在人工智能领域顶级学术会议和期刊发表了大量研究成果,其中MindVLA-o1相关的多篇论文已在CVPR、ICLR、ICRA、AAAI等国际顶会上发表。未来,理想汽车将继续以用户价值为导向,投入前沿研究以及核心技术自研,持续构建面向物理世界智能的完整AI系统,坚定迈向全球领先的具身智能企业。(资料来源:理想汽车)



1、“国际在线”由中国国际广播电台主办。经中国国际广播电台授权,国广国际在线网络(北京)有限公司独家负责“国际在线”网站的市场经营。
2、凡本网注明“来源:国际在线”的所有信息内容,未经书面授权,任何单位及个人不得转载、摘编、复制或利用其他方式使用。
3、“国际在线”自有版权信息(包括但不限于“国际在线专稿”、“国际在线消息”、“国际在线XX消息”“国际在线报道”“国际在线XX报道”等信息内容,但明确标注为第三方版权的内容除外)均由国广国际在线网络(北京)有限公司统一管理和销售。
已取得国广国际在线网络(北京)有限公司使用授权的被授权人,应严格在授权范围内使用,不得超范围使用,使用时应注明“来源:国际在线”。违反上述声明者,本网将追究其相关法律责任。
任何未与国广国际在线网络(北京)有限公司签订相关协议或未取得授权书的公司、媒体、网站和个人均无权销售、使用“国际在线”网站的自有版权信息产品。否则,国广国际在线网络(北京)有限公司将采取法律手段维护合法权益,因此产生的损失及为此所花费的全部费用(包括但不限于律师费、诉讼费、差旅费、公证费等)全部由侵权方承担。
4、凡本网注明“来源:XXX(非国际在线)”的作品,均转载自其它媒体,转载目的在于传递更多信息,丰富网络文化,此类稿件并不代表本网赞同其观点和对其真实性负责。
5、如因作品内容、版权和其他问题需要与本网联系的,请在该事由发生之日起30日内进行。



